本文共 53080 字,大约阅读时间需要 176 分钟。
目录
基础
数据结构
1、值类型:
bool int(32 or 64), int8, int16, int32, int64 uint(32 or 64), uint8(byte), uint16, uint32, uint64 float32, float64 string complex64, complex128 array -- 固定长度的数组字符
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
var a := '中' var b := 'x'Go 语言的字符有以下两种:
- uint8类型,或者叫byte 型,代表了ASCII码的一个字符。
- rune类型,代表一个 UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。 Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
// 遍历字符串 func traversalString() { s := "pprof.cn博客" for i := 0; i < len(s); i++ { //byte fmt.Printf("%v(%c) ", s[i], s[i]) } fmt.Println() for _, r := range s { //rune fmt.Printf("%v(%c) ", r, r) } fmt.Println() } // 112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 229(å) 141() 154() 229(å) 174(®) 162(¢) 112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 21338(博) 23458(客) 因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是只读不能修改的,字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
字符串
常用操作:
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.Contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
s1 := "123"byteS1 := []byte(s1)byteS1[0] = 'a'fmt.Print(string(byteS1))s2 := "中国123"byteS2 := []rune(s2)byteS2[0] = '我'fmt.Print(string(byteS2))数组
func arrayTest() { a := [2]int{ 1, 2} b := [...]int{ 1, 2, 3} c := [4]int{ 0: 1, 3: 10} d := [...]struct { name string age uint8 }{ { "a1", 10}, { "a2", 10}, } fmt.Println(a, b, c, d) // aM := [2][3]int{ { 1, 2, 3}, { 4, 5, 6}} bM := [...][2]int{ { 1, 2}} //纬度不能用 "..."。 fmt.Println(aM, bM) }// 值拷贝和传指针func test(x [2]int) { fmt.Printf("x: %p\n", &x) x[1] = 1000}func test2(arr *[5]int) { arr[0] = 10}func testCopy() { a := [2]int{ } fmt.Printf("a: %p\n", &a) //值拷贝 test(a) fmt.Println(a) var arr1 [5]int //数组指针 test2(&arr1) fmt.Println(arr1) arr2 := [...]int{ 2, 4, 6, 8, 10} test2(&arr2) fmt.Println(arr2)}//a: 0xc000064210//x: 0xc000064220//[0 0]//[10 0 0 0 0]//[10 4 6 8 10]//数组指针和指针数组 ....2、引用类型:(指针类型)
slice -- 动态长度的数组 map -- 映射 chan -- 管道3、指针
func testPointer() { s := "123" var sp *string sp = &s fmt.Println(*sp) //var pp *int只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new函数对a进行初始化之后就可以正常对其赋值了 var pp *int pp = new(int) *pp = 12 // a := new(int) //初始化了一个int类型的指针 b := new(bool) fmt.Printf("%T\n", a) // *int fmt.Printf("%T\n", b) // *bool fmt.Println(*a) // 0 fmt.Println(*b) // false // // 指针数组 cA := [1]*int{ pp} fmt.Println(cA) aA := [2]int{ 1, 2} // 数组指针 var pA *[2]int pA = &aA fmt.Println(*pA)}内置函数
Go 语言拥有一些不需要进行导入操作就可以使用的内置函数。它们有时可以针对不同的类型进行操作,例如:len、cap 和 append,或必须用于系统级的操作,例如:panic。因此,它们需要直接获得编译器的支持。
append -- 用来追加元素到数组、slice中,返回修改后的数组、slice close -- 主要用来关闭channel delete -- 从map中删除key对应的value panic -- 停止常规的goroutine (panic和recover:用来做错误处理) recover -- 允许程序定义goroutine的panic动作 real -- 返回complex的实部 (complex、real imag:用于创建和操作复数) imag -- 返回complex的虚部 make -- 用来分配内存,返回Type本身(只能应用于slice, map, channel) new -- 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针 cap -- capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map) copy -- 用于复制和连接slice,返回复制的数目 len -- 来求长度,比如string、array、slice、map、channel ,返回长度buf := make([]byte, 1024)对于引用类型(slice、map、chan)的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的new和make。 Go语言中new和make是内建的两个函数,主要用来分配内存。
make与new
- 二者都是用来做内存分配的。
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- new用于值类型和struct的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。根据传入的类型分配一片内存空间并返回指向这片内存空间的指针。使用new函数得到的是一个类型的指针。
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。
defer
defer 会在当前函数返回前执行传入的函数,它会经常被用于关闭文件描述符、关闭数据库连接、关闭http的响应body,回滚数据库的事务以及解锁资源。
预计算参数:
func main() { startedAt := time.Now() defer fmt.Println(time.Since(startedAt)) time.Sleep(time.Second)}$ go run main.go0s调用 defer 关键字会立刻拷贝函数中引用的外部参数,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s。
解决方法只需要向 defer 关键字传入匿名函数,虽然调用 defer 关键字时也使用值传递,但是因为拷贝的是函数指针,所以 time.Since(startedAt) 会在 main 函数返回前调用并打印出符合预期的结果。
func main() { startedAt := time.Now() defer func() { fmt.Println(time.Since(startedAt)) }() time.Sleep(time.Second)}$ go run main.go1s1、堆上分配 · 1.1 ~ 1.12
defer的数据结构如下。
type _defer struct { siz int32//参数和结果的内存大小 started bool openDefer bool sp uintptr//栈指针 pc uintptr//调用方的程序计数器 fn *funcval//defer关键字中传入的函数 _panic *_panic link *_defer // 延迟调用链表}- 编译期将 defer 关键字被转换 runtime.deferproc 并在调用 defer 关键字的函数返回之前插入 runtime.deferreturn;
- 运行时调用 runtime.deferproc 会将一个新的 runtime._defer 结构体追加到当前 Goroutine 的链表头;
- 运行时调用 runtime.deferreturn 会从 Goroutine 的链表中取出 runtime._defer 结构并依次执行;
2、栈上分配 · 1.13
- 当defer关键字在函数体中最多执行一次时,编译期间的 cmd/compile/internal/gc.state.call 会将结构体分配到栈上并调用 。
3、开放编码 · 1.14 ~ 现在
通过开放编码(Open Coded)实现 defer 关键字,该设计使用代码内联优化 defer 关键的额外开销并引入函数数据 funcdata 管理 panic 的调用。开放编码只会在满足以下的条件时启用:函数的 defer 数量少于或者等于 8 个;函数的 defer 关键字不能在循环中执行;函数的 return 语句与 defer 语句的乘积小于或者等于 15 个;
- 编译期间判断 defer 关键字、return 语句的个数确定是否开启开放编码优化;
- 通过 deferBits 和 cmd/compile/internal/gc.openDeferInfo 存储 defer 关键字的相关信息;
- 如果 defer 关键字的执行可以在编译期间确定,会在函数返回前直接插入相应的代码,否则会由运行时的 runtime.deferreturn 处理;
结构体
Tag
Tag是Struct的一部分,只有在反射场景中才有用,而反射包中提供了操作Tag的方法。常见的tag用法,主要是JSON数据解析、ORM映射等。struct结合反射获取tag中的键值。
type Server struct { ServerName string `key1:"value1" key11:"value11"` ServerIP string `key2:"value2"`}func main() { s := Server{ } st := reflect.TypeOf(s) field1 := st.Field(0) fmt.Printf("key1:%v\n", field1.Tag.Get("key1")) fmt.Printf("key11:%v\n", field1.Tag.Get("key11")) filed2 := st.Field(1) fmt.Printf("key2:%v\n", filed2.Tag.Get("key2"))}接口
接口是计算机系统中多个组件共享的边界,不同的组件能够在边界上交换信息。如下图所示,接口的本质是引入一个新的中间层,调用方可以通过接口与具体实现分离,解除上下游的耦合,上层的模块不再需要依赖下层的具体模块,只需要依赖一个约定好的接口。rpc远程过程调用。
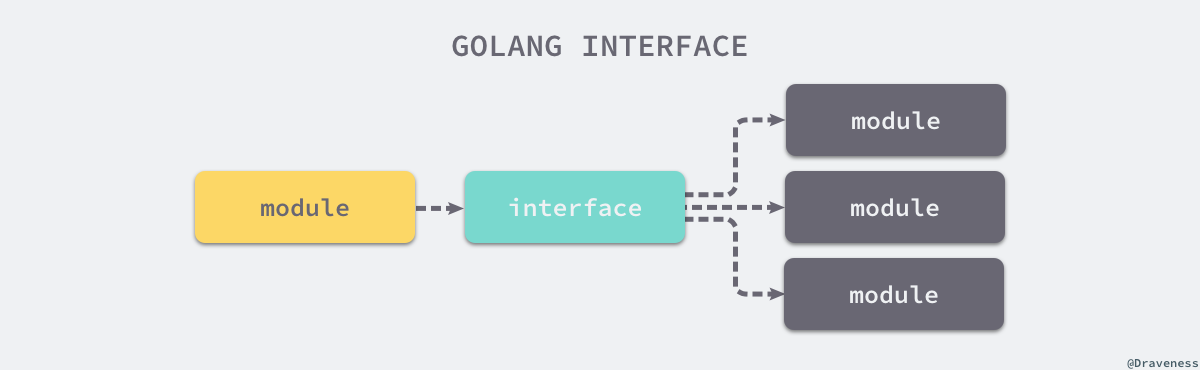
在 Go 中:实现接口的所有方法就隐式地实现了接口,不需要java中显示的实现接口。使用结构体时并不关心它实现了哪些接口,Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查。
type error interface { Error() string}type RPCError struct { Code int64 Message string}func (e *RPCError) Error() string { return fmt.Sprintf("%s, code=%d", e.Message, e.Code)}func NewRPCError(code int64, msg string) error { return &RPCError{ // typecheck3 Code: code, Message: msg, }}func AsErr(err error) error { return err}func main() { var rpcErr error = NewRPCError(400, "unknown err") // typecheck1 err := AsErr(rpcErr) // typecheck2 println(err)}在编译期间对代码进行类型检查,上述代码总共触发了三次类型检查:
- 将 *RPCError 类型的变量赋值给 error 类型的变量 rpcErr;
- 将 *RPCError 类型的变量 rpcErr 传递给签名中参数类型为 error 的 AsErr 函数;
- 将 *RPCError 类型的变量从函数签名的返回值类型为 error 的 NewRPCError 函数中返回;
当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。
package maintype TestStruct struct{ }func NilOrNot(v interface{ }) bool { return v == nil}func main() { var s *TestStruct fmt.Println(s == nil) // #=> true fmt.Println(NilOrNot(s)) // #=> false}上述代码中调用 NilOrNot 函数时发生了隐式的类型转换,除了向方法传入参数之外,变量的赋值也会触发隐式类型转换。在类型转换时,*TestStruct 类型会转换成 interface{}类型,转换后的变量不仅包含转换前的变量,还包含变量的类型信息 TestStruct,所以转换后的变量与 nil 不相等。
类型转换:
任意的结构体都能转换为空接口类型
空接口类型转换为结构体类型:类型断言、类型转换、强制类型转换
type Duck interface { Quack()}type Cat struct { Name string}func (c *Cat) Quack() { println(c.Name + " meow")}func testC1() { var c Duck = &Cat{ Name: "123"} switch c.(type) { case *Cat: a := c.(*Cat)//类型断言 a.Quack() }}func testC2() { var c interface{ } = &Cat{ Name: "draven"} switch c.(type) { case *Cat: cat := c.(*Cat) cat.Quack() }}动态派发:
接口不同的结构体的实现,多态。两种:直接指定结构体;赋值给接口,运行时决定哪个实现的结构体
func main() { var c Duck = &Cat{ Name: "draven"}//DynamicDispatch c.Quack() c.(*Cat).Quack()//DirectCall}空接口:
任何类型都可以被Any类型引用,Any类型就是空接口,即interface{}
反射
很多框架(gorm、json)都依赖 Go 语言的反射机制简化代码。因为 Go 语言的语法元素很少、设计简单,所以它没有特别强的表达能力,但是 Go 语言的 reflect 包能够弥补它在语法上reflect.Type的一些劣势。reflect 实现了运行时的反射能力,能够让程序操作不同类型的对象。反射包中有两对非常重要的函数和类型,两个函数分别是:reflect.TypeOf 能获取类型信息;reflect.ValueOf 能获取数据的运行时表示;
func testReflect() { s := "12344" fmt.Println(reflect.TypeOf(s)) fmt.Println(reflect.ValueOf(s)) // 动态修改变量 i := 1 v := reflect.ValueOf(&i) v.Elem().SetInt(10) fmt.Println(i)}type CustomError struct{ }func (*CustomError) Error() string { return ""}func testImplementInterface() { //判断类型是否实现了某些接口 typeOfError := reflect.TypeOf((*error)(nil)).Elem() customErrorPtr := reflect.TypeOf(&CustomError{ }) customError := reflect.TypeOf(CustomError{ }) fmt.Println(customErrorPtr.Implements(typeOfError)) // #=> true fmt.Println(customError.Implements(typeOfError)) // #=> false}func Add(a, b int) int { return a + b }func testCall() { //动态调用方法 v := reflect.ValueOf(Add) if v.Kind() != reflect.Func { return } t := v.Type() argv := make([]reflect.Value, t.NumIn()) for i := range argv { if t.In(i).Kind() != reflect.Int { return } argv[i] = reflect.ValueOf(i) } result := v.Call(argv) if len(result) != 1 || result[0].Kind() != reflect.Int { return } fmt.Println(result[0].Int()) // #=> 1}错误异常
错误是业务过程的一部分,而异常不是可以使程序的内部错误。错误例如业务中的前置校验,异常为程序内部的抛错(数组越界等)。很多其他语言中有try…catch关键词,用来捕获异常情况,但是其实很多错误都是可以预期发生的,而不需要异常处理,应该当做错误来处理,这也是为什么Go语言采用了函数返回错误的设计,这些函数不会panic,例如如果一个文件找不到,os.Open返回一个错误,它不会panic;如果你向一个中断的网络连接写数据,net.Conn系列类型的Write函数返回一个错误,它们不会panic。这些状态在这样的程序里都是可以预期的。
func Sqrt(a float64) (float64, error) { if a < 0 { return 1, errors.New("123") } return math.Sqrt(a), nil}错误和异常 Go中错误和异常是有明显的区分。有一些操作几乎不可能失败,而且在一些特定的情况下也没有办法返回错误,也无法继续执行,这样情况就应该panic。举个例子:如果一个程序计算x[j],但是j越界了,这部分代码就会导致panic,像这样的一个不可预期严重错误就会引起panic,在默认情况下它会杀掉进程,它允许一个正在运行这部分代码的goroutine从发生错误的panic中恢复运行,发生panic之后,这部分代码后面的函数和代码都不会继续执行,这是Go特意这样设计的,因为要区别于错误和异常,panic其实就是异常处理。如下代码,我们期望通过uid来获取User中的username信息,但是如果uid越界了就会抛出异常,这个时候如果我们没有recover机制,进程就会被杀死,从而导致程序不可服务。因此为了程序的健壮性,在一些地方需要建立recover机制。
如果你定义的函数有可能失败,它就应该返回一个错误。
func GetUser(uid int) (username string) { defer func() { if x := recover(); x != nil { username = "" } }() username = User[uid] return}panic和recover
应用:
- panic 能够改变程序的控制流,调用 panic 后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的 defer;
- recover 可以中止 panic 造成的程序崩溃。它是一个只能在 defer 中发挥作用的函数,在其他作用域中调用不会发挥作用**,recover 只有在发生 panic 之后调用才会生效,需要在 defer 中使用 recover 关键字。**
func main() { defer func() { fmt.Println("123") if err := recover(); err != nil { fmt.Println(err) } }() testPanic()}func testPanic() { panic("raise panic")}//123//raise panic原理:
每当我们调用 panic 都会创建一个如下所示的数据结构存储相关信息:
type _panic struct { argp unsafe.Pointer//defer 调用时参数的指针 arg interface{ }//调用 panic 时传入的参数; link *_panic//更早调用的 runtime._panic 结构,因此支持多次调用panic函数 recovered bool//当前 runtime._panic 是否被 recover 恢复 aborted bool//当前的 panic 是否被强行终止 pc uintptr sp unsafe.Pointer goexit bool}程序崩溃恢复:
1、编译器会负责做转换关键字的工作;
将 panic 和 recover 分别转换成 runtime.gopanic 和 runtime.gorecover;
将 defer 转换成 runtime.deferproc 函数;在调用 defer 的函数末尾调用 runtime.deferreturn 函数;
2、在运行过程中遇到 runtime.gopanic 方法时,会从 Goroutine 的链表依次取出 runtime.defer 结构体并执行;
3、如果调用延迟执行函数时遇到了 runtime.gorecover 就会将 panic.recovered 标记成 true 并返回 panic 的参数;
在这次调用结束之后,runtime.gopanic 会从 runtime.defer 结构体中取出程序计数器 pc 和栈指针 sp 并调用 runtime.recovery 函数进行恢复程序;
runtime.recovery 会根据传入的 pc 和 sp 跳转回 runtime.deferproc;
编译器自动生成的代码会发现 runtime.deferproc 的返回值不为 0,这时会跳回 runtime.deferreturn 并恢复到正常的执行流程;
4、如果没有遇到 runtime.gorecover 就会依次遍历所有的 runtime.defer,并在最后调用 runtime.fatalpanic 中止程序、打印 panic 的参数并返回错误码 2;
其他
强制类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
func sqrtDemo() { var a, b = 3, 4 var c int c = int(math.Sqrt(float64(a*a + b*b))) fmt.Println(c)}调试工具
Go语言不像PHP、Python等动态语言,只要修改不需要编译就可以直接输出,而且可以动态的在运行环境下打印数据。当然Go语言也可以通过Println之类的打印数据来调试,但是每次都需要重新编译,这是一件相当麻烦的事情。
GDB作为调试工具可以用于调试Go程序的一些基本命令,包括run、print、info、set variable、coutinue、list、break 等经常用到的调试命令。。。
## go文件。。。## 编译文件,生成可执行文件gdbfile:go build -gcflags "-N -l" gdbfile.go## 通过gdb命令启动调试:gdb gdbfile测试用例
1、单元测试
testing内置库,go test
2、性能压力测试
压力测试用来检测函数(方法)的性能。go test不会默认执行压力测试的函数,如果要执行压力测试需要带上参数-test.bench,语法:test.bench=“test_name_regex”,例如go test -test.bench=".*"表示测试全部的压力测试函数
Z:\src\go\gotest>go test gotest_test.go -test.bench=".*"goos: windowsgoarch: amd64Benchmark_Division-4 1000000000 0.473 ns/opBenchmark_TimeConsumingFunction-4 1000000000 0.467 ns/opPASSok command-line-arguments 1.425s注意点
引用:http://topgoer.com/%E8%B5%84%E6%96%99%E4%B8%8B%E8%BD%BD/Golang%E6%96%B0%E6%89%8B%E5%8F%AF%E8%83%BD%E4%BC%9A%E8%B8%A9%E7%9A%8450%E4%B8%AA%E5%9D%91.html
json
以小写字母开头的字段成员是无法被外部直接访问的,所以 struct 在进行 json、xml、gob 等格式的 encode 操作时,这些私有字段会被忽略。
http
使用 HTTP 标准库发起请求、获取响应时,即使你不从响应中读取任何数据或响应为空,都需要手动关闭响应体。应该先检查 HTTP 响应错误为 nil,再调用 resp.Body.Close() 来关闭响应体:
func main() { resp, err := http.Get("http://www.baidu.com") // 关闭 resp.Body 的正确姿势 if resp != nil { defer resp.Body.Close() } checkError(err) defer resp.Body.Close() body, err := ioutil.ReadAll(resp.Body) checkError(err) fmt.Println(string(body))}一些支持 HTTP1.1 或 HTTP1.0 配置了 connection: keep-alive 选项的服务器会保持一段时间的长连接。但标准库 “net/http” 的连接默认只在服务器主动要求关闭时才断开,所以你的程序可能会消耗完 socket 描述符。解决办法有 2 个,请求结束后:
- 直接设置请求变量的 Close 字段值为 true,每次请求结束后就会主动关闭连接。
- 设置 Header 请求头部选项 Connection: close,然后服务器返回的响应头部也会有这个选项,此时 HTTP 标准库会主动断开连接。
根据需求选择使用场景:
- 若你的程序要向同一服务器发大量请求,使用默认的保持长连接。
- 若你的程序要连接大量的服务器,且每台服务器只请求一两次,那收到请求后直接关闭连接。或增加最大文件打开数 fs.file-max 的值。
range迭代
三种方式迭代slice、map,分为没有返回值、1个、2个。在 range 迭代中,得到的值其实是元素的一份值拷贝,更新拷贝并不会更改原来的元素,即是拷贝的地址并不是原有元素的地址:
func main() { data := []int{ 1, 2, 3} for _, v := range data { v *= 10 // data 中原有元素是不会被修改的 } fmt.Println("data: ", data) // data: [1 2 3]}如果要修改原有元素的值,应该使用索引直接访问:
func main() { data := []int{ 1, 2, 3} for i, v := range data { data[i] = v * 10 } fmt.Println("data: ", data) // data: [10 20 30]}如果你的集合保存的是指向值的指针,需稍作修改。依旧需要使用索引访问元素,不过可以使用 range 出来的元素直接更新原有值:
func main() { data := []*struct{ num int }{ { 1}, { 2}, { 3},} for _, v := range data { v.num *= 10 // 直接使用指针更新 } fmt.Println(data[0], data[1], data[2]) // &{10} &{20} &{30}}值比较
可以使用相等运算符 == 来比较结构体变量,前提是两个结构体的成员都是可比较的类型:
type data struct { num int fp float32 complex complex64 str string char rune yes bool events <-chan string handler interface{ } ref *byte raw [10]byte}func main() { v1 := data{ } v2 := data{ } fmt.Println("v1 == v2: ", v1 == v2) // true}如果两个结构体中有任意成员是不可比较的,将会造成编译错误。注意数组成员只有在数组元素可比较时候才可比较。
type data struct { num int checks [10]func() bool // 无法比较 doIt func() bool // 无法比较 m map[string]string // 无法比较 bytes []byte // 无法比较}func main() { v1 := data{ } v2 := data{ } fmt.Println("v1 == v2: ", v1 == v2)}invalid operation: v1 == v2 (struct containing [10]func() bool cannot be compared)
Go 提供了一些库函数来比较那些无法使用 == 比较的变量,比如使用 “reflect” 包的 DeepEqual() :
// 比较相等运算符无法比较的元素func main() { v1 := data{ } v2 := data{ } fmt.Println("v1 == v2: ", reflect.DeepEqual(v1, v2)) // true m1 := map[string]string{ "one": "a", "two": "b"} m2 := map[string]string{ "two": "b", "one": "a"} fmt.Println("v1 == v2: ", reflect.DeepEqual(m1, m2)) // true s1 := []int{ 1, 2, 3} s2 := []int{ 1, 2, 3} // 注意两个 slice 相等,值和顺序必须一致 fmt.Println("v1 == v2: ", reflect.DeepEqual(s1, s2)) // true}这种比较方式可能比较慢,根据你的程序需求来使用。DeepEqual() 还有其他用法:
func main() { var b1 []byte = nil b2 := []byte{ } fmt.Println("b1 == b2: ", reflect.DeepEqual(b1, b2)) // false}注意:
- DeepEqual() 并不总适合于比较 slice
func main() { var str = "one" var in interface{ } = "one" fmt.Println("str == in: ", reflect.DeepEqual(str, in)) // true v1 := []string{ "one", "two"} v2 := []string{ "two", "one"} fmt.Println("v1 == v2: ", reflect.DeepEqual(v1, v2)) // false data := map[string]interface{ }{ "code": 200, "value": []string{ "one", "two"}, } encoded, _ := json.Marshal(data) var decoded map[string]interface{ } json.Unmarshal(encoded, &decoded) fmt.Println("data == decoded: ", reflect.DeepEqual(data, decoded)) // false}如果要大小写不敏感来比较 byte 或 string 中的英文文本,可以使用 “bytes” 或 “strings” 包的 ToUpper() 和 ToLower() 函数。比较其他语言的 byte 或 string,应使用 bytes.EqualFold() 和 strings.EqualFold()
如果 byte slice 中含有验证用户身份的数据(密文哈希、token 等),不应再使用 reflect.DeepEqual()、bytes.Equal()、 bytes.Compare()。这三个函数容易对程序造成 timing attacks,此时应使用 “crypto/subtle” 包中的 subtle.ConstantTimeCompare() 等函数
- reflect.DeepEqual() 认为空 slice 与 nil slice 并不相等,但注意 byte.Equal() 会认为二者相等:
func main() { var b1 []byte = nil b2 := []byte{ } // b1 与 b2 长度相等、有相同的字节序 // nil 与 slice 在字节上是相同的 fmt.Println("b1 == b2: ", bytes.Equal(b1, b2)) // true}闭包函数
即 for 中创建的闭包函数接收到的参数始终是同一个变量,在 goroutine 开始执行时都会得到同一个迭代值:
func main() { data := []string{ "one", "two", "three"} for _, v := range data { go func() { fmt.Println(v) }() } time.Sleep(3 * time.Second) // 输出 three three three}最简单的解决方法:无需修改 goroutine 函数,在 for 内部使用局部变量保存迭代值,再传参:
func main() { data := []string{ "one", "two", "three"} for _, v := range data { vCopy := v go func() { fmt.Println(vCopy) }() } time.Sleep(3 * time.Second) // 输出 one two three}另一个解决方法:直接将当前的迭代值以参数形式传递给匿名函数:
func main() { data := []string{ "one", "two", "three"} for _, v := range data { go func(in string) { fmt.Println(in) }(v) } time.Sleep(3 * time.Second) // 输出 one two three}defer
对 defer 延迟执行的函数,会在调用它的函数结束时执行,而不是在调用它的语句块结束时执行,注意区分开。比如在一个长时间执行的函数里,内部 for 循环中使用 defer 来清理每次迭代产生的资源调用,就会出现问题。
解决办法:defer 延迟执行的函数写入匿名函数中。当然也可以去掉 defer,在文件资源使用完毕后,直接调用 f.Close() 来关闭。
// 目录遍历正常func main() { // ... for _, target := range targets { func() { f, err := os.Open(target) if err != nil { fmt.Println("bad target:", target, "error:", err) return // 在匿名函数内使用 return 代替 break 即可 } defer f.Close() // 匿名函数执行结束,调用关闭文件资源 }() }}gorutinue
func First(query string, replicas []Search) Result { c := make(chan Result) replicaSearch := func(i int) { c <- replicas[i](query) } for i := range replicas { go replicaSearch(i) } return <-c}在搜索重复时依旧每次都起一个 goroutine 去处理,每个 goroutine 都把它的搜索结果发送到结果 channel 中,channel 中收到的第一条数据会直接返回。返回完第一条数据后,其他 goroutine 的搜索结果怎么处理?他们自己的协程如何处理?在 First() 中的结果 channel 是无缓冲的,这意味着只有第一个 goroutine 能返回,由于没有 receiver,其他的 goroutine 会在发送上一直阻塞。如果你大量调用,则可能造成资源泄露。
为避免泄露,你应该确保所有的 goroutine 都能正确退出,有3 个解决方法:
- 使用带缓冲的 channel,确保能接收全部 goroutine 的返回结果:
func First(query string, replicas ...Search) Result { c := make(chan Result,len(replicas)) searchReplica := func(i int) { c <- replicas[i](query) } for i := range replicas { go searchReplica(i) } return <-c}- 使用 select 语句,配合能保存一个缓冲值的 channel default 语句: default 的缓冲 channel 保证了即使结果 channel 收不到数据,也不会阻塞 goroutine
func First(query string, replicas ...Search) Result { c := make(chan Result,1) searchReplica := func(i int) { select { case c <- replicas[i](query): default: } } for i := range replicas { go searchReplica(i) } return <-c}- 使用特殊的废弃(cancellation) channel 来中断剩余 goroutine 的执行:
func First(query string, replicas ...Search) Result { c := make(chan Result) done := make(chan struct{ }) defer close(done) searchReplica := func(i int) { select { case c <- replicas[i](query): case <- done: } } for i := range replicas { go searchReplica(i) } return <-c}进阶
编译
中间代码
Go 语言的应用程序在运行之前需要先编译成二进制,在编译的过程中会经过中间代码生成阶段,Go 语言编译器的中间代码具有静态单赋值(Static Single Assignment、SSA)的特性。可以通过命令将 Go 语言的源代码编译成汇编语言,然后通过汇编语言分析程序具体的执行过程,对其进行编译性能优化。
调试go源码:修改源码,标准库–>./src/make.bash–>*** run main.go
编译
编译,代码在运行之前需要通过编译器生成二进制机器码,包含二进制机器码的文件才能在目标机器上运行。
Go 语言编译器的源代码在 src/cmd/compile 目录中,目录下的文件共同组成了 Go 语言的编译器,编译器分为前端和后端,编译器的前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作,而编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的二进制机器码。
编译器在逻辑上可以被分成四个阶段:词法与语法分析、类型检查和 AST 转换、通用 SSA 中间代码生成、最后的机器代码生成。
slice
底层数据结构
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片的结构体由3部分构成,Pointer 是数组指针,len 代表当前切片的长度,cap 是当前切片的容量。cap 总是大于等于 len 的。
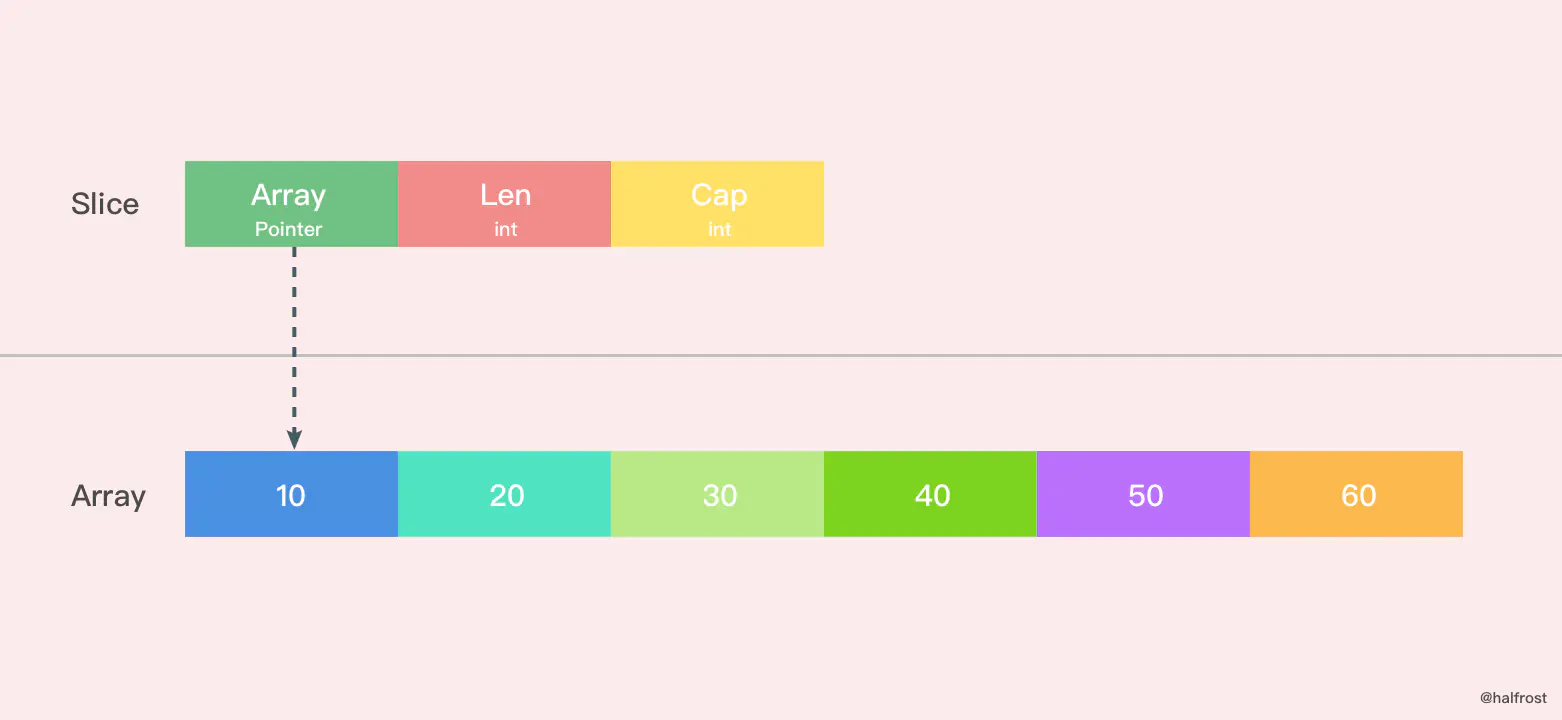
创建切片
1、make创建
// make sliceslice := make([]byte, 3)//空切片和nil切片的区别在于,空切片指向的地址不是nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。var emptySlice []int //nilsilce := make( []int , 0 )//空切片slice := []int{ }//空切片//func makeslice(et *_type, len, cap int) unsafe.Pointer { mem, overflow := math.MulUintptr(et.size, uintptr(cap)) if overflow || mem > maxAlloc || len < 0 || len > cap { // NOTE: Produce a 'len out of range' error instead of a // 'cap out of range' error when someone does make([]T, bignumber). // 'cap out of range' is true too, but since the cap is only being // supplied implicitly, saying len is clearer. // See golang.org/issue/4085. mem, overflow := math.MulUintptr(et.size, uintptr(len)) if overflow || mem > maxAlloc || len < 0 { panicmakeslicelen() } panicmakeslicecap() } // 分配连续的一块内存 return mallocgc(mem, et, true)}2、切片初始化创建
func main() { slice := []int{ 10, 20, 30, 40} newSlice := append(slice, 50) fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice)) fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice)) newSlice[1] += 10 fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice)) fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))}// Before slice = [10 20 30 40], Pointer = 0xc4200b0140, len = 4, cap = 4 Before newSlice = [10 20 30 40 50], Pointer = 0xc4200b0180, len = 5, cap = 8 After slice = [10 20 30 40], Pointer = 0xc4200b0140, len = 4, cap = 4 After newSlice = [10 30 30 40 50], Pointer = 0xc4200b0180, len = 5, cap = 8生成了新的切片,是因为原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原切片。
3、字面量创建
b := [5]int{ 1, 2, 3, 4, 5}c := b[2:4:5] //[low:high:max] len=high-low, cap=max-low // [3 4]func main() { array := [4]int{ 10, 20, 30, 40} slice := array[0:2] newSlice := append(slice, 50) fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice)) fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice)) newSlice[1] += 10 fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice)) fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice)) fmt.Printf("After array = %v\n", array)}// Before slice = [10 20], Pointer = 0xc4200c0040, len = 2, cap = 4 Before newSlice = [10 20 50], Pointer = 0xc4200c0060, len = 3, cap = 4 After slice = [10 30], Pointer = 0xc4200c0040, len = 2, cap = 4 After newSlice = [10 30 50], Pointer = 0xc4200c0060, len = 3, cap = 4 After array = [10 30 50 40]扩容以后并没有新建一个新的数组,扩容前后的数组都是同一个,这也就导致了新的切片修改了一个值,也影响到了老的切片了。并且 append() 操作也改变了原来数组里面的值。一个 append() 操作影响了这么多地方,如果原数组上有多个切片,那么这些切片都会被影响。这种情况,由于原数组还有容量可以扩容,所以执行 append() 操作以后,会在原数组上直接操作,所以这种情况下,扩容以后的数组还是指向原来的数组。这种情况也极容易出现在字面量创建切片时候,第三个参数 cap 传值的时候,如果用字面量创建切片,cap 并不等于指向数组的总容量,那么这种情况就会发生。建议用字面量创建切片的时候,cap 的值一定要保持清醒,避免共享原数组导致的 bug。
扩容
使用append向Slice追加元素时,如果Slice空间不足,将会触发Slice扩容,扩容实际上是重新分配一块更大的内存,将原Slice数据拷贝进新Slice,然后返回新Slice,扩容后再将数据追加进去。
func growslice(et *_type, old slice, cap int) slice { if raceenabled { callerpc := getcallerpc() racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice)) } if msanenabled { msanread(old.array, uintptr(old.len*int(et.size))) } if cap < old.cap { panic(errorString("growslice: cap out of range")) } if et.size == 0 { // append should not create a slice with nil pointer but non-zero len. // We assume that append doesn't need to preserve old.array in this case. return slice{ unsafe.Pointer(&zerobase), old.len, cap} } newcap := old.cap doublecap := newcap + newcap if cap > doublecap { newcap = cap } else { if old.len < 1024 { newcap = doublecap } else { // Check 0 < newcap to detect overflow // and prevent an infinite loop. for 0 < newcap && newcap < cap { newcap += newcap / 4 } // Set newcap to the requested cap when // the newcap calculation overflowed. if newcap <= 0 { newcap = cap } } } var overflow bool var lenmem, newlenmem, capmem uintptr // Specialize for common values of et.size. // For 1 we don't need any division/multiplication. // For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant. // For powers of 2, use a variable shift. switch { case et.size == 1: lenmem = uintptr(old.len) newlenmem = uintptr(cap) capmem = roundupsize(uintptr(newcap)) overflow = uintptr(newcap) > maxAlloc newcap = int(capmem) case et.size == sys.PtrSize: lenmem = uintptr(old.len) * sys.PtrSize newlenmem = uintptr(cap) * sys.PtrSize capmem = roundupsize(uintptr(newcap) * sys.PtrSize) overflow = uintptr(newcap) > maxAlloc/sys.PtrSize newcap = int(capmem / sys.PtrSize) case isPowerOfTwo(et.size): var shift uintptr if sys.PtrSize == 8 { // Mask shift for better code generation. shift = uintptr(sys.Ctz64(uint64(et.size))) & 63 } else { shift = uintptr(sys.Ctz32(uint32(et.size))) & 31 } lenmem = uintptr(old.len) << shift newlenmem = uintptr(cap) << shift capmem = roundupsize(uintptr(newcap) << shift) overflow = uintptr(newcap) > (maxAlloc >> shift) newcap = int(capmem >> shift) default: lenmem = uintptr(old.len) * et.size newlenmem = uintptr(cap) * et.size capmem, overflow = math.MulUintptr(et.size, uintptr(newcap)) capmem = roundupsize(capmem) newcap = int(capmem / et.size) } // The check of overflow in addition to capmem > maxAlloc is needed // to prevent an overflow which can be used to trigger a segfault // on 32bit architectures with this example program: // // type T [1<<27 + 1]int64 // // var d T // var s []T // // func main() { // s = append(s, d, d, d, d) // print(len(s), "\n") // } if overflow || capmem > maxAlloc { panic(errorString("growslice: cap out of range")) } var p unsafe.Pointer if et.ptrdata == 0 { p = mallocgc(capmem, nil, false) // The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length). // Only clear the part that will not be overwritten. memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem) } else { // Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory. p = mallocgc(capmem, et, true) if lenmem > 0 && writeBarrier.enabled { // Only shade the pointers in old.array since we know the destination slice p // only contains nil pointers because it has been cleared during alloc. bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem) } } memmove(p, old.array, lenmem) return slice{ p, old.len, newcap}}切片扩容的策略:
**如果切片的容量小于 1024 个元素,于是扩容的时候就翻倍增加容量。一旦元素个数超过 1024 个元素,那么增长因子就变成 1.25 ,即每次增加原来容量的四分之一。**注意:扩容扩大的容量都是针对原来的容量而言的,而不是针对原来数组的长度而言的。
新数组 or 老数组 :
再谈谈扩容之后的数组一定是新的么?这个不一定,分情况。。。
注意:
当切片中的元素大小等于 sys.PtrSize 8时,扩容函数会将待申请的内存向上取整,取整时会使用 runtime.class_to_size 数组,使用该数组中的整数可以提高内存的分配效率并减少碎片。
如下代码会触发 runtime.growslice 函数扩容 arr 切片并传入期望的新容量 5,这时期望分配的内存大小为 40 字节;不过因为切片中的元素大小等于 sys.PtrSize,所以运行时会调用 runtime.roundupsize 向上取整内存的大小到 48 字节,所以新切片的容量为 48 / 8 = 6。
var arr []int64arr = append(arr, 1, 2, 3, 4, 5)fmt.Println(cap(arr)) //6切片拷贝
通过 runtime.memmove 将整块内存的内容拷贝到目标的内存区域中。相比于依次拷贝元素,runtime.memmove 能够提供更好的性能。需要注意的是,整块拷贝内存仍然会占用非常多的资源,在大切片上执行拷贝操作时一定要注意对性能的影响。
array := []int{ 10, 20, 30, 40}slice := make([]int, 6)n := copy(slice, array)fmt.Println(n, slice)//4 [10 20 30 40 0 0]索引 迭代
引用:http://topgoer.com/go%E5%9F%BA%E7%A1%80/Slice%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0.html
slice应用
package mainimport ( "fmt")func AddElement(slice []int, e int) []int { return append(slice, e)}func main() { var slice []int slice = append(slice, 1, 2, 3) newSlice := AddElement(slice, 4) fmt.Println(&slice[0] == &newSlice[0])}//append函数执行时会判断切片容量是否能够存放新增元素,如果不能,则会重新申请存储空间,新存储空间将是原来的2倍或1.25倍(取决于扩展原空间大小),本例中实际执行了两次append操作,第一次空间增长到4,所以第二次append不会再扩容,所以新旧两个切片将共用一块存储空间。程序会输出”true”。map
map的业界实现方式有两种:开放寻址法和拉链法
1、开放地址法
底层完全是一个单个的数组实现。
写数据时,当 Key3 与已经存入哈希表中的两个键值对 Key1 和 Key2 发生冲突时,Key3 会被写入 Key2 后面的空闲位置。当我们再去读取 Key3 对应的值时就会先获取键的哈希并取模,这会先帮助我们找到 Key1,找到 Key1 后发现它与 Key 3 不相等,所以会继续查找后面的元素,直到内存为空或者找到目标元素。
读取数据时,当需要查找某个键对应的值时,会从索引的位置开始线性探测数组,找到目标键值对或者空内存就意味着这一次查询操作的结束。开放寻址法中对性能影响最大的是装载因子,它是数组中元素的数量与数组大小的比值。随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会影响哈希表的读写性能。当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入任意元素的时间复杂度都是 O(n)O(n) 的,这时需要遍历数组中的全部元素,所以在实现哈希表时一定要关注装载因子的变化。
2、拉链法
与开放地址法相比,拉链法是哈希表最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
实现拉链法一般会使用数组加上链表,不过一些编程语言会在拉链法的哈希中引入红黑树以优化性能,拉链法会使用链表数组作为哈希底层的数据结构,我们可以将它看成可以扩展的二维数组。桶的数组 + 桶里的链表
哈希算法的要求:哈希函数的结果能够尽可能的均匀分布,然后通过工程上的手段解决哈希碰撞的问题。
基础应用
func testMap() { myMap := make(map[string]int, 8) myMap["a"] = 1 fmt.Println(myMap)}数据结构
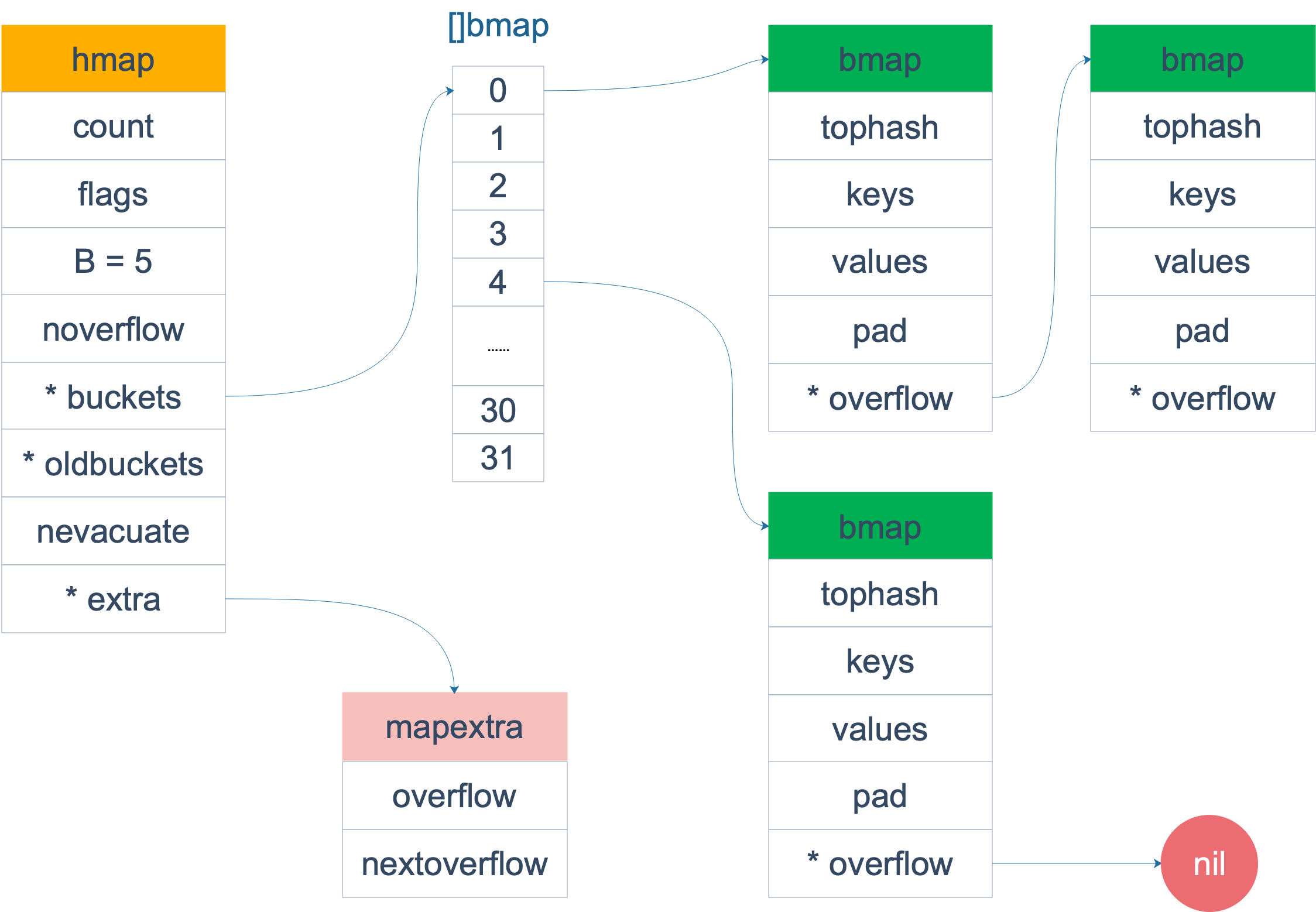
Golang的map使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即bucket桶,而每个bucket就保存了map中的一个或一组键值对。map数据结构由runtime/map.go:hmap定义:
type hmap struct { count int // 当前保存的元素个数 ... B uint8 //可以计算出桶的数量,即哈希表的长度,大小为2^B ... buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B oldbuckets unsafe.Pointer // 扩缩容搬迁时使用 ...}下图展示一个拥有4个bucket的map:
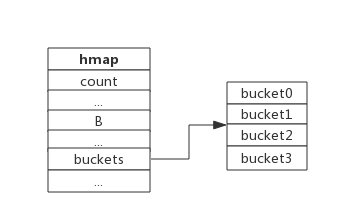
本例中, hmap.B=2, 而hmap.buckets长度是2^B为4. 元素经过哈希运算后会落到某个bucket中进行存储。查找过程类似。
bucket很多时候被翻译为桶,所谓的哈希桶实际上就是bucket。
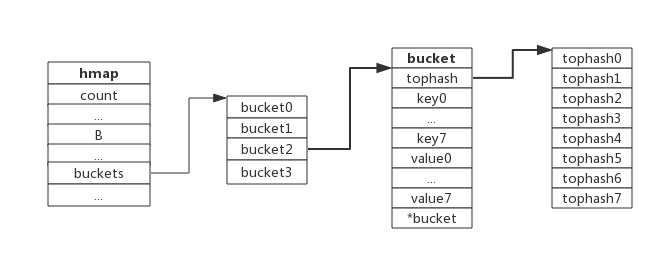
bucket数据结构由runtime/map.go:bmap定义:
type bmap struct { tophash [8]uint8 //存储哈希值的高8位 data byte[1] //key value数据:key/key/key/.../value/value/value... overflow *bmap //溢出bucket的地址}每个bucket可以存储8个键值对。
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
注意:上述中data和overflow并不是在结构体中显示定义的,而是直接通过指针运算进行访问的。下图展示bucket存放8个key-value对:
负载因子
负 载 因 子 = 元 素 总 数 量 / b u c k e t 数 量 负载因子 = 元素总数量/bucket数量 负载因子=元素总数量/bucket数量
例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1.哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存1个键值对,而Go的bucket可能存8个键值对,所以Go可以容忍更高的负载因子。
查找过程
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 取哈希值的高8位在tophash数组中查询
- 如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行进一步的比较
- 当前bucket没有找到,则继续从下个overflow的bucket中查找。
- 如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
插入过程
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果没找到将key,将key插入
扩容
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。触发扩容的条件有二个:
- 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
- overflow溢出桶的数量 > 2^15时,也即overflow数量超过32768时。
扩容不是一个原子的过程,所以 runtime.mapassign 还需要判断当前哈希是否已经处于扩容状态,避免二次扩容造成混乱。
扩容过程不是原子的,而是通过 runtime.growWork 增量触发的,在扩容期间访问哈希表时会使用旧桶,向哈希表写入数据时会触发旧桶元素的分流(新数据到新的桶老数据还在老的桶)。除了这种正常的扩容之外,为了解决大量写入、删除造成的内存泄漏问题,哈希引入了 sameSizeGrow 这一机制,在出现较多溢出桶时会整理哈希的内存减少空间的占用。
map的扩容不会立马全部复制,而是渐进式增量的扩容,即首先开辟2倍的内存空间,创建一个新的bucket数组。只有当访问原来就的bucket数组时,才会将就得bucket拷贝到新的bucket数组,进行渐进式的扩容。当然旧的数据不会删除,而是去掉引用,等待gc回收。
增量扩容
当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
等量扩容
如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容 sameSizeGrow。实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。在极端场景下,比如不断地增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况。
引用:http://wen.topgoer.com/docs/gozhuanjia/gozhuanjiamap
总结
Go 语言使用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了对应的运行时函数或者方法。哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为可以帮助哈希快速遍历桶中元素的缓存快速判断key是否存在,遍历正常桶和后面的所有的溢出桶,每个元素的前8位的hash相同的key,再去对比key的值是否相同。
哈希表的每个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
哈希表的随机遍历:底层原理,随机选择一个索引位置的桶,先遍历正常桶的键值,再遍历后面溢出桶。继续遍历下一个索引位置的桶。
string
string可以为空(长度为0),但不会是nil;string对象不可以修改。字符串是一个只读的字节切片。
数据结构:其中包含指向字节数组的指针和数组的大小。
字符串不允许修改:
Go的实现中,string不包含内存空间,只有一个内存的指针,这样做的好处是string变得非常轻量,可以很方便的进行传递而不用担心内存拷贝。因为string通常指向字符串字面量,而字符串字面量存储位置是只读段,而不是堆或栈上,所以才有了string不可修改的约定。
string和[]byte如何取舍:
string和[]byte都可以表示字符串,但因数据结构不同,其衍生出来的方法也不同,要根据实际应用场景来选择。
string 擅长的场景:
- 需要字符串比较的场景;
- 不需要nil字符串的场景;
[]byte擅长的场景:
- 修改字符串的场景,尤其是修改粒度为1个字节;
- 函数返回值,需要用nil表示含义的场景;
- 需要切片操作的场景;
虽然看起来string适用的场景不如[]byte多,但因为string直观,在实际应用中还是大量存在,在偏底层的实现中[]byte使用更多,写文件,网络传输需要将转换为字节流。
chan
channel是Golang在语言层面提供的goroutine间的通信方式,比Unix管道更易用也更轻便。channel主要用于进程内各goroutine间通信,如果需要跨进程通信,建议使用分布式系统的方法来解决。
type hchan struct { qcount uint // 当前队列中剩余元素个数 dataqsiz uint // 环形队列长度,即可以存放的元素个数 buf unsafe.Pointer // 环形队列指针 elemsize uint16 // 每个元素的大小 closed uint32 // 标识关闭状态 elemtype *_type // 元素类型 sendx uint // 队列下标,指示元素写入时存放到队列中的位置 recvx uint // 队列下标,指示元素从队列的该位置读出 recvq waitq // 等待读消息的goroutine队列 sendq waitq // 等待写消息的goroutine队列 lock mutex // 互斥锁,chan不允许并发读写}从数据结构可以看出channel由队列、类型信息、goroutine等待队列组成。
等待队列
从channel读数据,如果channel缓冲区为空或者没有缓冲区,当前goroutine会被阻塞。
向channel写数据,如果channel缓冲区已满或者没有缓冲区,当前goroutine会被阻塞。
被阻塞的goroutine将会挂在channel的等待队列中:
- 因读阻塞的goroutine会被向channel写入数据的goroutine唤醒;
- 因写阻塞的goroutine会被从channel读数据的goroutine唤醒;
下图展示了一个没有缓冲区的channel,有几个goroutine阻塞等待读数据:
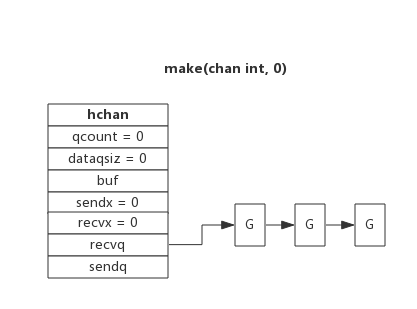
创建channel的过程实际上是初始化hchan结构。其中类型信息和缓冲区长度由make语句传入,buf的大小则与元素大小和缓冲区长度共同决定。
向channel写数据
向一个channel中写数据简单过程如下:
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据写入,最后把该G唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤醒;
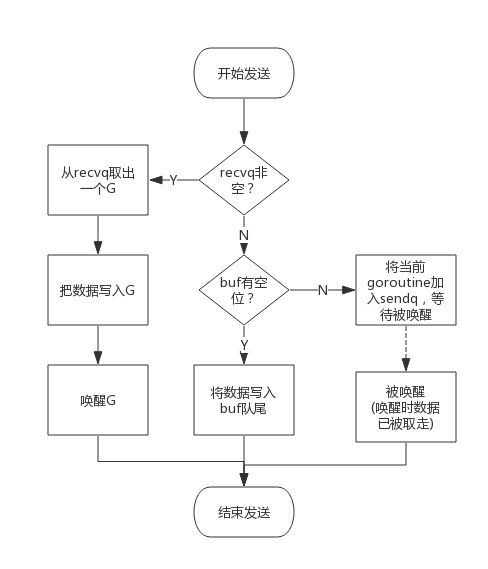
从channel读数据
从一个channel读数据简单过程如下:
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
- 将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
简单流程图如下:
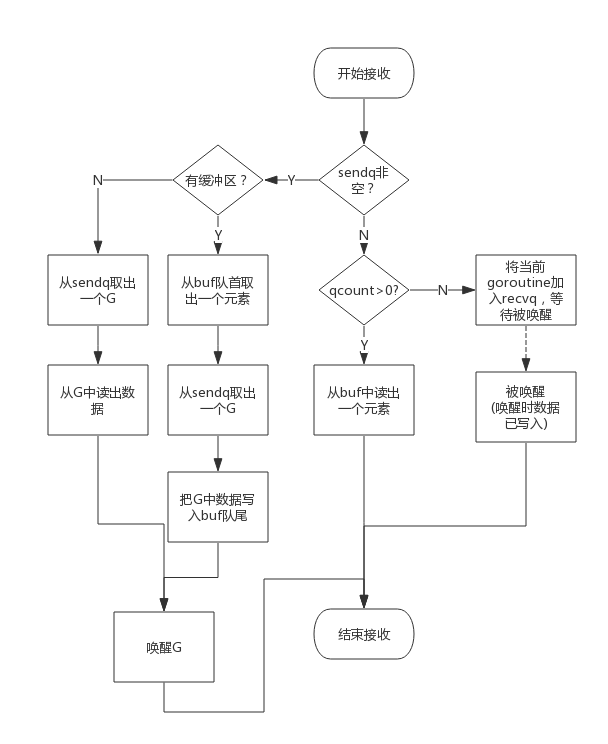
关闭channel
关闭channel时会把recvq中的G全部唤醒,本该写入G的数据位置为nil。把sendq中的G全部唤醒,但这些G会panic。
除此之外,panic出现的常见场景还有:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
引用:http://wen.topgoer.com/docs/gozhuanjia/gochan4
遍历chan
for v := range ch {} 的语句最终会被转换成如下的格式
ha := ahv1, hb := <-hafor ; hb != false; hv1, hb = <-ha { v1 := hv1 hv1 = nil ...}该循环会使用 <-ch从管道中取出等待处理的值,这个操作会调用 并阻塞当前的协程,当 返回时会根据布尔值 hb 判断当前的值是否存在:
- 如果不存在当前值,意味着当前的管道已经被关闭;
- 如果存在当前值,会为 v1 赋值并清除 hv1 变量中的数据,然后重新陷入阻塞等待新数据;
select
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。
select { case <-chan1: // 如果chan1成功读到数据,则进行该case处理语句 case chan2 <- 1: // 如果成功向chan2写入数据,则进行该case处理语句 default: // 如果上面都没有成功,则进入default处理流程 }select 也能够让 Goroutine 同时等待多个 Channel 可读或者可写,在多个文件或者 Channel状态改变之前,select 会一直阻塞当前线程或者 Goroutine。
1、select的非阻塞:通过default保证。2、随机性:select的两个case如果都是同时满足执行条件的,如果我们按照顺序依次判断,那么后面的条件永远都会得不到执行,而随机的引入就是为了避免饥饿问题的发生。
并发控制
channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
通道有发送(send)、接收(receive)和关闭(close)三种操作。
无缓冲的通道和带缓冲的通道 :
无缓冲的通道只有在有人接收值的时候才能发送值。就像你住的小区没有快递柜和代收点,快递员给你打电话必须要把这个物品送到你的手中,简单来说就是无缓冲的通道必须有接收才能发送。使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道,阻塞通道。
同步机制
go中用于同步的方式有很多种,常见的有:原子操作、互斥锁、读写锁、waitgroup。Go代码中可能会存在多个goroutine同时操作一个资源(临界区),这种情况会发生竞态问题(数据竞态)。
Mutex
当一个变量被上了互斥锁后,其他访问该变量的线程会被堵塞,不可对该变量进行读写操作,直到锁被释放。互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个goroutine可以访问共享资源。
RWMutex
A RWMutex is a reader/writer mutual exclusion lock.
RWMutex是基于互斥锁Mutex实现的,包含了读锁Rlock()和写锁Lock(),上读锁时,数据可以被多个goroutine并发访问但不可写,而上写锁时,数据不可被其他goroutine读或写。读写锁非常适合读多写少的场景。
sync.WaitGroup
waitgroup在golang中的实现都依赖于 原子操作 & 信号量,go中的信号量是在runtime包中实现的。Golang中的信号量,提供了goroutine的阻塞和唤醒机制。
var x int64var wg sync.WaitGroupfunc add() { for i := 0; i < 5000; i++ { x = x + 1 } wg.Done() //-1}func main() { wg.Add(2) go add() go add() wg.Wait() //同步等待完成 fmt.Println(x)}参考:https://zhuanlan.zhihu.com/p/33462152
sync.Once
需要确保某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等。sync.Once其实内部**包含一个互斥锁和一个布尔值,互斥锁保证布尔值和数据的安全,而布尔值用来记录初始化是否完成。**这样设计就能保证初始化操作的时候是并发安全的并且初始化操作也不会被执行多次。
加载载配置文件。延迟一个开销很大的初始化操作到真正用到它的时候再执行是一个很好的实践。因为预先初始化一个变量(比如在init函数中完成初始化)会增加程序的启动耗时,而且有可能实际执行过程中这个变量没有用上,那么这个初始化操作就不是必须要做的。我们来看一个例子:
var icons map[string]image.Imagefunc loadIcons() { icons = map[string]image.Image{ "left": loadIcon("left.png"), "up": loadIcon("up.png"), "right": loadIcon("right.png"), "down": loadIcon("down.png"), }}// Icon 被多个goroutine调用时不是并发安全的func Icon(name string) image.Image { if icons == nil { //....failed loadIcons() } return icons[name]}多个goroutine并发调用Icon函数时不是并发安全的,现代的编译器和CPU可能会在保证每个goroutine都满足串行一致的基础上自由地重排访问内存的顺序(指令重排)。loadIcons函数可能会被重排为以下结果。在这种情况下就会出现即使判断了icons不是nil也不意味着变量初始化完成了。考虑到这种情况,我们能想到的办法就是添加互斥锁,保证初始化icons的时候不会被其他的goroutine操作,但是这样做又会引发性能问题。
func loadIcons() { icons = make(map[string]image.Image) icons["left"] = loadIcon("left.png") icons["up"] = loadIcon("up.png") icons["right"] = loadIcon("right.png") icons["down"] = loadIcon("down.png")}使用sync.Once改造的示例代码如下:
var icons map[string]image.Imagevar loadIconsOnce sync.Oncefunc loadIcons() { icons = map[string]image.Image{ "left": loadIcon("left.png"), "up": loadIcon("up.png"), "right": loadIcon("right.png"), "down": loadIcon("down.png"), }}func Icon(name string) image.Image { loadIconsOnce.Do(loadIcons) return icons[name]}sync.NewCond
var ( wg sync.WaitGroup m = sync.Mutex{ } c = sync.NewCond(&m) sharedRsc = false)func testCond() { wg.Add(2) go func() { c.L.Lock() for sharedRsc == false { fmt.Println("goroutine1 wait") c.Wait() //将释放c.L锁 } fmt.Println("goroutine1", sharedRsc) c.L.Unlock() wg.Done() }() go func() { c.L.Lock() for sharedRsc == false { fmt.Println("goroutine2 wait") c.Wait() } fmt.Println("goroutine2", sharedRsc) c.L.Unlock() wg.Done() }() time.Sleep(2 * time.Second)//等待所有子go进入wait c.L.Lock() fmt.Println("main goroutine ready") sharedRsc = true c.Broadcast() //c.Signal() 会死锁 fmt.Println("main goroutine broadcast") c.L.Unlock() wg.Wait()}1、执行结果如下。
goroutine1 waitgoroutine2 waitmain goroutine readymain goroutine broadcastgoroutine2 truegoroutine1 true2、删除main goroutine中的2s延时。执行结果如下。
main goroutine readymain goroutine broadcastgoroutine2 truegoroutine1 true3、如果我们在子goroutine中不做校验呢?我们会得到1个死锁。原因如下:
cond.Wait会释放锁并等待其他goroutine调用Broadcast或者Signal来通知其恢复执行,除此之外没有其他的恢复途径。但此时main goroutine已经调用了Broadcast并进入了等待状态,没有任何goroutine会去拯救还在cond.Wait中的子goroutine了,而该子goroutine也没有机会调用wg.Done()去恢复main goroutine,造成了死锁。
注意点:只有当线程获取到锁后才可以调用其关联的条件变量的wait方法,否则会抛出异常;当线程阻塞到wait方法后,当前线程会释放已经获取的锁;没有wait直接Broadcast可以的。
参考:https://ieevee.com/tech/2019/06/15/cond.html
sync.Pool
大量重复地创建许多对象,造成 GC 的工作量巨大,CPU 频繁掉底。可以使用 sync.Pool 来缓存对象,减轻 GC 的消耗。可以作为保存临时取还对象的一个“池子”。sync.Pool 是协程安全的,这对于使用者来说是极其方便的。使用前,设置好对象的 New 函数,用于在 Pool 里没有缓存的对象时,创建一个。之后,在程序的任何地方、任何时候仅通过 Get()、Put() 方法就可以取、还对象了。pool作为临时对象池子。
type Person struct{ Name string}var pool *sync.Poolfunc initPool(){ pool = &sync.Pool{ New: func()interface{ } { fmt.Println("creating a new person")//初始化对象池子 return new(Person) }, }}func testSyncPool() { initPool() p := pool.Get().(*Person) fmt.Println(p) p.Name = "wxd" pool.Put(p) p = pool.Get().(*Person) fmt.Println(p) p2 := Person{ "zwx"} pool.Put(&p2) fmt.Println(pool.Get().(*Person))}源码分析:https://juejin.cn/post/6844903903046320136#heading-6
sync.Map
Go语言中内置的map不是并发安全的。Go语言的sync包中提供了一个开箱即用的并发安全版map–sync.Map。
var m = sync.Map{ }func main() { wg := sync.WaitGroup{ } for i := 0; i < 20; i++ { wg.Add(1) go func(n int) { key := strconv.Itoa(n) m.Store(key, n) value, _ := m.Load(key) fmt.Printf("k=:%v,v:=%v\n", key, value) wg.Done() }(i) } wg.Wait()}atomic
代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法它在用户态就可以完成,因此性能比加锁操作更好。Go语言中原子操作原子类由内置的标准库sync/atomic提供。这里原子操作,是保证多个cpu(协程)对同一块内存区域的操作是原子的。CAS操作,为了保证原子性,golang是通过汇编指令来实现的。
atomic.CompareAndSwapInt32()//源值的地址、原值、目标值调度模型
GOMAXPROCS
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码。默认值是机器上的CPU核心数。例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上(GOMAXPROCS是m:n调度中的n)。Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。Go1.5版本之前,默认使用的是单核心执行。Go1.5版本之后,默认使用全部的CPU逻辑核心数。
Go语言中的操作系统线程和goroutine的关系:
- 1.一个操作系统线程对应用户态多个goroutine。
- 2.go程序可以同时使用多个操作系统线程。
- 3.goroutine和OS线程是多对多的关系,即m:n。
GMP
Go 调度本质是把大量的 goroutine 分配到少量线程上去执行,并利用多核并行,实现更强大的并发。
线程分为 “内核态 “线程和” 用户态 “线程。一个 “用户态线程” 必须要绑定一个 “内核态线程”,但是 CPU 并不知道有 “用户态线程” 的存在,它只知道它运行的是一个 “内核态线程”(Linux 的 PCB 进程控制块)。内核线程依然叫 “线程 (thread)”,用户线程叫 “协程 (co-routine)”。
Go 为了提供更容易使用的并发方法,使用了 goroutine 和 channel。goroutine 来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被 runtime 调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。Go 中,协程被称为 goroutine,它非常轻量,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发。虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime会自动为 goroutine 分配。
Goroutine 特点:
- 占用内存更小(几 kb)
- 调度更灵活 (runtime 调度)
GMP:调度协程的调度器。**M (thread线程) 和 G (goroutine协程) P (Processor调度器)。**Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。M 与 P 是 1:1 的关系。
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。
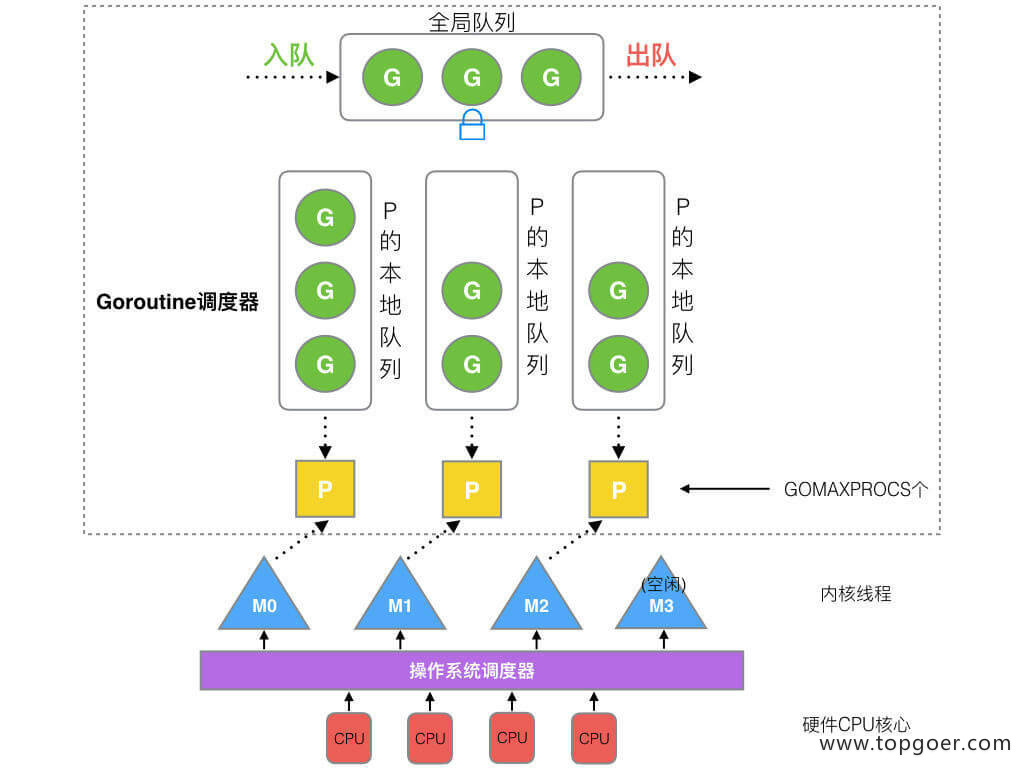
- 全局队列(Global Queue):存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS(可配置) 个。
- M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行。
1、P 的数量:由启动时环境变量 GOMAXPROCS 或者是由 runtime 的方法 GOMAXPROCS() 决定。这意味着在程序执行的任意时刻都只有 GOMAXPROCS 个 goroutine 在同时运行。
2、M 的数量:go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000. 但是内核很难支持这么多的线程数,所以这个限制可以忽略。runtime/debug 中的 SetMaxThreads 函数,设置 M 的最大数量一个 M 阻塞了,会创建新的 M。
M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
P 和 M 何时会被创建:
1、P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P。
2、M 何时创建:没有足够的 M 来关联 P 并运行其中的可运行的 G。比如所有的 M 此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的 M,而没有空闲的,就会去创建新的 M。
调度器的策略:
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
1)work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
2)hand off 机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局 G 队列:在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
引用:http://topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/GMP%E5%8E%9F%E7%90%86%E4%B8%8E%E8%B0%83%E5%BA%A6.html
runtime
go的调度器
runtime.GOMAXPROCS(1)//设置逻辑处理器个数,也就是设置GMP中的P的个数runtime.Gosched()//类似Java中线程的yeild方法,当一个goroutine执行该方法时候意味着当前goroutine放弃当前cpu的使用权,然后运行时会调度系统会调度其他goroutine占用cpu进行运行,放弃CPU使用权的goroutine并没有被阻塞,而是处于就绪状态,可以在随时获取到cpu情况下继续运行debug.SetMaxThreads(threads int)//设置最多可以创建多少操作系统线程M内存管理
内存池:
分配器的数据结构包括:
-
MHeap: 分配堆,按页的粒度进行理(4kB)
-
MCache: 用于小对象的每M一个的cache
-
FixAlloc: 固定大小(128kB)的对象的空闲链分配器,被分配器用于管理存储
-
MSpan: 一些由MHeap管理的页
-
MCentral: 对于给定尺寸类别的共享的free list
在多线程方面,很自然的做法就是每条线程都有自己的本地的内存,然后有一个全局的分配链,当某个线程中内存不足后就向全局分配链中申请内存。这样就避免了多线程同时访问共享变量时的加锁。 在避免内存碎片方面,大块内存直接按页为单位分配,小块内存会切成各种不同的固定大小的块,申请做任意字节内存时会向上取整到最接近的块,将整块分配给申请者以避免随意切割。
Go中为每个系统线程分配一个本地的MCache(前面介绍的结构体M中的MCache域),少量的地址分配就直接从MCache中分配,并且定期做垃圾回收,将线程的MCache中的空闲内存返回给全局控制堆。小于32K为小对象,大对象直接从全局控制堆上以页(4k)为单位进行分配,也就是说大对象总是以页对齐的。一个页可以存入一些相同大小的小对象,小对象从本地内存链表中分配,大对象从中心内存堆中分配。
GC:
Go语言中使用的垃圾回收使用的是标记清扫算法。进行垃圾回收时会stoptheworld。不过,在当前1.3版本中,实现了精确的垃圾回收和并行的垃圾回收,大大地提高了垃圾回收的速度,进行垃圾回收时系统并不会长时间卡住。
标记清扫算法是一个很基础的垃圾回收算法,该算法中有一个标记初始的root区域,以及一个受控堆区。root区域主要是程序运行到当前时刻的栈和全局数据区域。在受控堆区中,很多数据是程序以后不需要用到的,这类数据就可以被当作垃圾回收了。判断一个对象是否为垃圾,就是看从root区域的对象是否有直接或间接的引用到这个对象。如果没有任何对象引用到它,则说明它没有被使用,因此可以安全地当作垃圾回收掉。
标记清扫算法分为两阶段:标记阶段和清扫阶段。标记阶段,从root区域出发,扫描所有root区域的对象直接或间接引用到的对象,将这些对上全部加上标记。在回收阶段,扫描整个堆区,对所有无标记的对象进行回收。
三色标记法:
。。。
GC回收时机:
垃圾回收的触发是由一个gcpercent的变量控制的,当新分配的内存占已在使用中的内存的比例超过gcprecent时就会触发。比如,gcpercent=100,当前使用了4M的内存,那么当内存分配到达8M时就会再次gc。如果回收完毕后,内存的使用量为5M,那么下次回收的时机则是内存分配达到10M的时候。也就是说,并不是内存分配越多,垃圾回收频率越高,这个算法使得垃圾回收的频率比较稳定,适合应用的场景。gcpercent的值是通过环境变量GOGC获取的,如果不设置这个环境变量,默认值是100。如果将它设置成off,则是关闭垃圾回收。
内存对齐
参考:https://juejin.cn/post/6844904067244769294 https://zhuanlan.zhihu.com/p/53413177
操作系统的cpu不是一个字节一个字节访问内存的,是按2,4,8这样的字长来访问的。如32位系统访问粒度是4字节(bytes),64位系统的是8字节。当被访问的数据长度为 n 字节且该数据地址为n字节对齐,那么操作系统就可以高效地一次定位到数据,无需多次读取、处理对齐运算等额外操作。空间换时间的方法,数据结构应该尽可能地在自然边界上对齐。如果访问未对齐的内存,CPU 需要做两次内存访问。
内存对齐是为了cpu更高效访问内存中数据。struct的对齐是:如果类型 t 的对齐保证是 n,那么类型 t 的每个值的地址在运行时必须是 n 的倍数。struct中的字段,填充成对齐粒度的倍数。
源码
http
。。。
sql
通用接口
Driver、Conn、Tx Stmt(statement sql查询语句)、Results Rows Row、Value
SQL 是应用程序和数据库之间的中间层,应用程序在多数情况下都不需要关心底层数据库的实现,它们只关心 SQL 查询返回的数据。Go 语言的 database/sql 就建立在上述前提下,我们可以使用相同的 SQL 语言查询关系型数据库,所有关系型数据库的客户端都需要实现如下所示的驱动接口:
type Driver interface { Open(name string) (Conn, error)}type Conn interface { Prepare(query string) (Stmt, error) Close() error Begin() (Tx, error)}database/sql/driver.Driver 接口中只包含一个 Open 方法,该方法接收一个数据库连接串作为输入参数并返回一个特定数据库的连接,作为参数的数据库连接串是数据库特定的格式,这个返回的连接仍然是一个接口,整个标准库中的全部接口可以构成如下所示的树形结构:
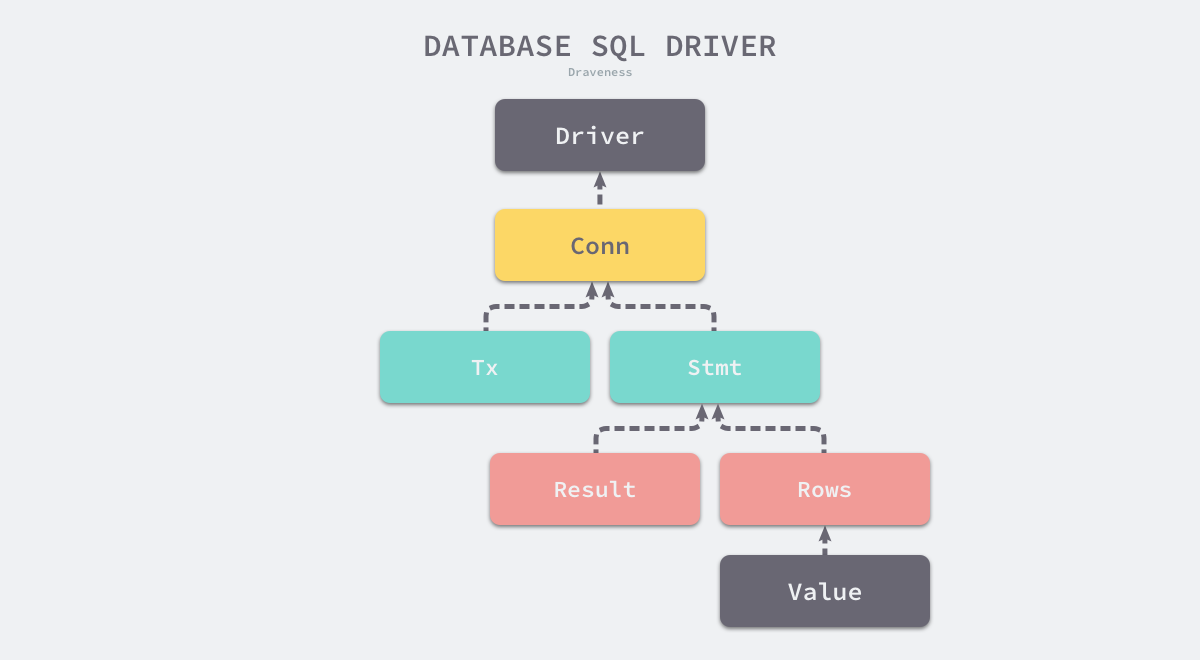
连接池
https://zhuanlan.zhihu.com/p/109852936
https://juejin.cn/post/6844903924017659911
https://blog.crazytaxii.com/posts/golang_sql_connection_pool/ 源!
1、驱动注册
是注册不同的数据源,比如MySQL、PostgreSQL等,这些数据源具体实现了Conn、Tx Stmt、Results Rows、Value这些接口。
2、初始化DB
初始化DB即调用Open函数,这时候其实没有真的去获取DB操作的连接,只是初始化得到一个DB的数据结构。
DB的数据结构:关键点包括连接切片、请求的等待队列。
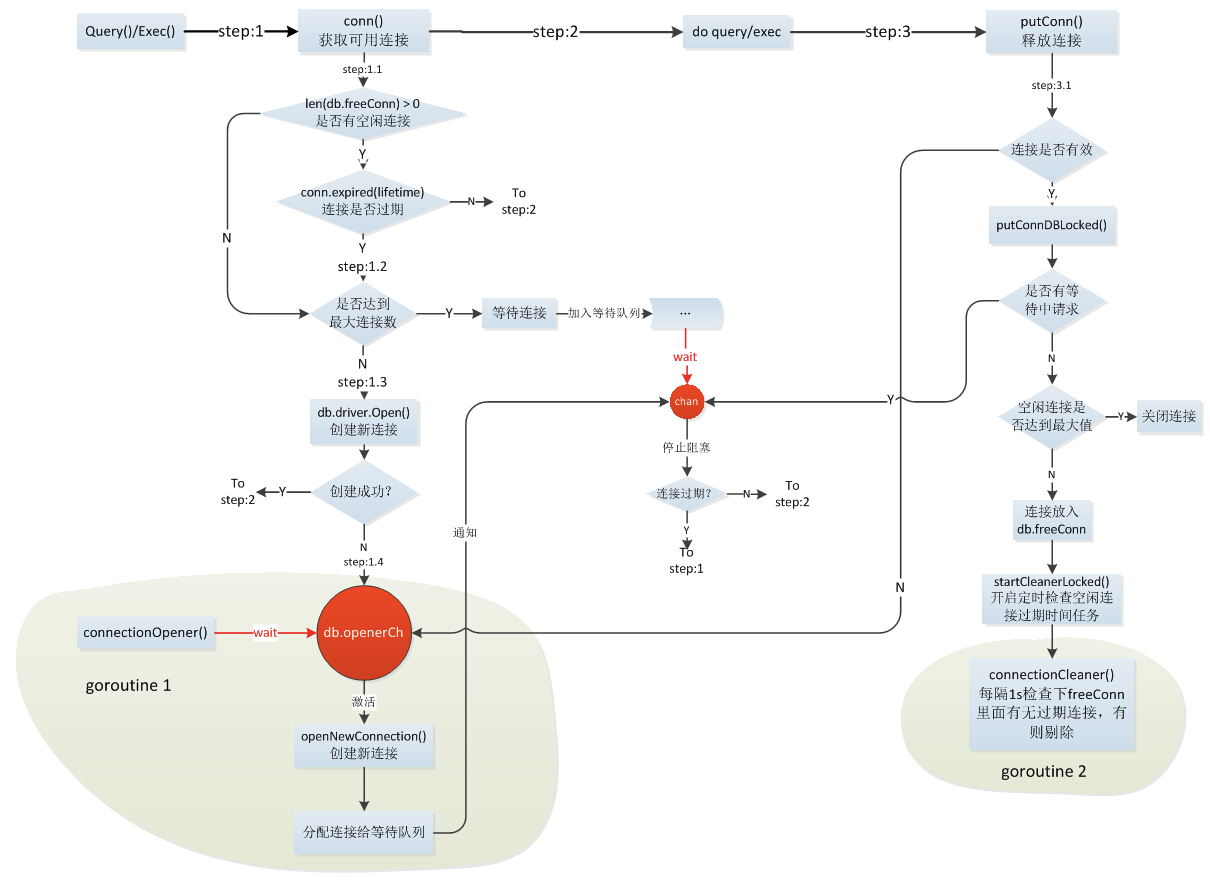
type DB struct { // Atomic access only. At top of struct to prevent mis-alignment // on 32-bit platforms. Of type time.Duration. waitDuration int64 // 等待新连接的总时间,用于统计 connector driver.Connector // 由数据库驱动实现的连接器 // numClosed is an atomic counter which represents a total number of // closed connections. Stmt.openStmt checks it before cleaning closed // connections in Stmt.css. numClosed uint64 // 关闭的连接数 mu sync.Mutex // 锁 freeConn []*driverConn // 可用连接池 connRequests map[uint64]chan connRequest // 连接请求表,key 是分配的自增键 nextRequest uint64 // 连接请求的自增键 numOpen int // 已经打开 + 即将打开的连接数 // Used to signal the need for new connections // a goroutine running connectionOpener() reads on this chan and // maybeOpenNewConnections sends on the chan (one send per needed connection) // It is closed during db.Close(). The close tells the connectionOpener // goroutine to exit. openerCh chan struct{ } // 告知 connectionOpener 需要新的连接 resetterCh chan *driverConn // connectionResetter 函数,连接放回连接池的时候会用到 closed bool dep map[finalCloser]depSet lastPut map[*driverConn]string // debug 时使用,记录上一个放回的连接 maxIdle int // 连接池大小,默认大小为 2,<= 0 时不使用连接池 maxOpen int // 最大打开的连接数,<= 0 不限制 maxLifetime time.Duration // 一个连接可以被重用的最大时限,也就是它在连接池中的最大存活时间,0 表示可以一直重用 cleanerCh chan struct{ } // 告知 connectionCleaner 清理连接 waitCount int64 // 等待的连接总数 maxIdleClosed int64 // 释放连接时,因为连接池已满而被关闭的连接总数 maxLifetimeClosed int64 // 因为超过存活时间而被关闭的连接总数 stop func() // stop cancels the connection opener and the session resetter.}3、获取连接
获取连接是在具体的sql语句中执行的,比如Query方法、Exec方法等。进入conn()方法的具体实现逻辑是如果连接池中有空闲的连接且没有过期的就直接拿出来用;如果当前实际连接数已经超过最大连接数即上面case中提到的maxOpenConns,则将任务添加到任务队列中等待;以上情况都不满足,则自行创建一个新的连接用于执行DB操作。
从连接池中获取连接时首先要对整个连接池加锁,如果连接池已经事先被关掉了,直接返回 errDBClosed 错误。如果连接池无恙,将会评估连接请求是否取消或过期。尽可能优先使用空闲的连接而不是新建一条连接(这也是连接池存在的意义)。看一下是否还剩下空闲连接,如果还有余粮,就取第 0 条连接出来,然后左移所有连接填补空位。这里对连接本身操作都会上锁。如果没有空闲连接了,而且已打开的 + 即将打开的连接数超过了限定的最大打开的连接数,就要发送一条连接请求然后排队(不会新建连接)。等待排队期间同时监听连接请求是否取消或过期,如果此时连接被取消很不巧正好有连接来了,就将连接放回连接池中;如果等着等着连接来了,会先检查这个连接的上一次会话是否被重置(擦屁股),确认没问题就用这条连接。
详见:https://blog.crazytaxii.com/posts/golang_sql_connection_pool/
如果还没到限定的最大打开的连接数,放心大胆的新建一条。
4、连接回池
当DB操作结束后,需要将连接释放,比如放回到连接池中,以便下一次DB操作的使用。释放连接的代码实现在sql.go中的putConn()方法。其主要做的工作是判定连接是否过期,如果没有过期则放回连接池。
连接池的完整实现逻辑如下图所示。
性能调优
。。。。。。
内存泄漏
参考:https://cloud.tencent.com/developer/article/1437506
泄漏场景:
其他的泄漏:读文件、http响应、context未释放
协程泄漏:大部分泄露的场景都是协程泄露。协程不会被释放;程序不断走这个创建协程
如果你启动了1个goroutine,但并没有符合预期的退出,直到程序结束,此goroutine才退出,这种情况就是goroutine泄露。每个goroutine占用2KB内存,泄露1百万goroutine至少泄露2KB * 1000000 = 2GB内存。goroutine泄露有2种方式造成内存泄露:goroutine本身的栈所占用的空间造成内存泄露。goroutine中的变量所占用的堆内存导致堆内存泄露,这一部分是能通过heap profile体现出来的。
goroutine泄露的本质是channel阻塞,无法继续向下执行,导致此goroutine关联的内存都无法释放,进一步造成内存泄露。或者协程内死循环,同时又会创建大量的这个协程,最终导致内存泄漏。
为避免goroutine泄露造成内存泄露,启动goroutine前要思考清楚:goroutine如何退出?是否会有阻塞造成无法退出?如果有,那么这个路径是否会创建大量的goroutine?
实战:
参考:https://www.cnblogs.com/CtripDBA/p/12289939.html
采用工具pprof内存泄漏监控工具,工具的使用与思路:
1)先修改源代码, 在主函数中新增端口启动监控程序,采用新开一个监听协程方式,防止阻塞,用于监控业务程序。重新启动业程序
2)安装工具观察 yum install golang pprof
3)使用命令对heap进行dump分析,这个工具的好处是dump后可以直接生成pdf或png,运行一次,过一段时间再运行一次,对比两次的结果的火焰图
4)修复内存缺陷代码, 再根据分析结果修复内存泄漏的地方
5)发布代码进行再跟踪分析
热点
字符和字节
字节(Byte)是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位,通常情况下一字节等于八位。字符(Character)计算机中使用的字母、数字、字和符号。根据编码方式的不同,一个中英文字符对应不同的个数的字节,常见的编码方式ASCII、Unicode、UTF-8(一个英文字符1个字节,一个中文3个字节)。
go中:
参考:https://blog.csdn.net/wohu1104/article/details/106202720
遍历字符串:索引字符串会产生其字节,而不是其字符 。在字符串上使用 for range 循环时,range 循环在每次迭代中会解码一个 UTF-8 编码 rune。
func main() { str := "Go爱好者" for i:=0;i<len(str);i++{ c := str[i] fmt.Printf("%d: %q [% x]\n", i, c, []byte(string(c))) } //... for i, c := range str { fmt.Printf("%d: %q [% x]\n", i, c, []byte(string(c))) } //0: 'G' [47] //1: 'o' [6f] //2: '爱' [e7 88 b1] //5: '好' [e5 a5 bd] //8: '者' [e8 80 85] }字符串只是一堆字节字符串类型,字符串是只读的 ,其底层数据结构包括一个是指针指向字节数组的起点,另一个是字符串的长度。len() 函数判断字符串长度的时候,是判断字符的字节数而不是字符长度。
a := "1a中国" fmt.Println(len(a)) //8 字符串中的字节的个数 fmt.Println(len([]rune(a))) //4 字符的个数 统计带中文的字符串的字符个数方法之一byte和rune:Go语言的两种类型的字符,一种是 byte 类型,byte 类型是 uint8 类型的一个别名 ,代表了 ASCII 码的一个字符。另一种是 rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型,rune 类型别名是 int32 类型。rune类型是为了更方便的表示类似中文的非英文字符,处理起来更加方便;而byte类型则对英文字符的处理更加友好。
slice底层
扩容的容量阈值1024 ,当小于它2倍的扩,当大于增加0.25的扩。
map底层
https://www.cnblogs.com/qcrao-2018/p/10903807.html
https://cloud.tencent.com/developer/article/1468799
$$
哈希表的长度=2^B。
负载因子=元素总个数/桶的个数。
$$
查找过程:计算出key的哈希值,位操作相当于取余哈希表的个数,找到桶的位置,根据哈希值的高8位在桶中找到对应其中的key,没有的话继续根据溢出桶的指针到溢出桶中去找。
插入过程:一个桶里面会最多装 8 个 键值,在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置。一个桶内最多有8个位置, 如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。
扩容:触发条件负载因子大于6.5或者溢出桶的个数过多。
chan
协程间通信。go的原则是通过通信共享内存,而不是其他语言的通过共享内存通信。带缓冲区的通道和不带缓冲区的通道。
select
语言层面的读写多路复用。
GMP模型
M内核线程,P处理器,P有个G的任务队列,G协程用户级线程。
GC
https://zhuanlan.zhihu.com/p/105495961/
引用计数、标记回收、分代
标记回收算法:
- 标记那些还在被引用的对象;
- 在堆中回收那些没被标记不被使用的对象
这个算法最大的问题是 GC 执行期间需要把整个程序完全暂停,不能异步进行 GC 操作。因为在不同阶段标记清扫法的标志位 0 和 1 有不同的含义,那么新增的对象无论标记为什么都有可能意外删除这个对象。对实时性要求高的系统来说,这种需要长时间挂起的标记清扫法是不可接受的。所以就需要一个算法来解决 GC 运行时程序长时间挂起的问题,那就三色标记法。
三色标记:
相比传统的标记清扫算法,三色标记最大的好处是可以异步执行,从而可以以中断时间极少的代价或者完全没有中断来进行整个 GC。
三色标记法很简单。首先将对象用三种颜色表示,分别是白色、灰色和黑色。最开始所有对象都是白色的,然后把其中全局变量和函数栈里的对象置为灰色。第二步把灰色的对象全部置为黑色,然后把原先灰色对象指向的变量都置为灰色,以此类推。等发现没有对象可以被置为灰色时,所有的白色变量就一定是需要被清理的垃圾了。
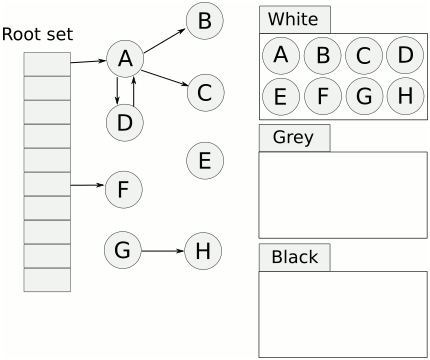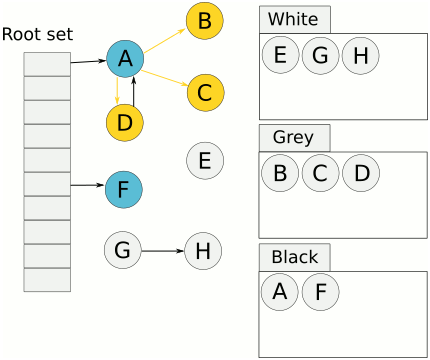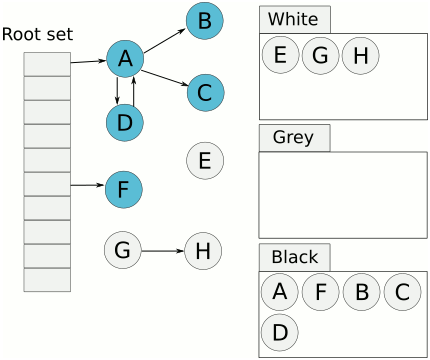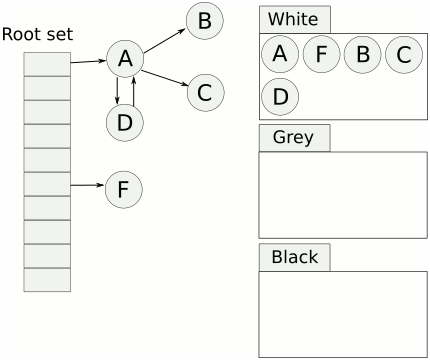
三色标记法因为多了一个白色的状态来存放不确定的对象,所以可以异步地执行。当然异步执行的代价是可能会造成一些遗漏,因为那些早先被标记为黑色的对象可能目前已经是不可达的了。所以三色标记法是一个 false negative(假阴性)的算法。除了异步标记的优点,三色标记法掌握了更多当前内存的信息,因此可以更加精确地按需调度,而不用像标记清扫法那样只能定时执行。